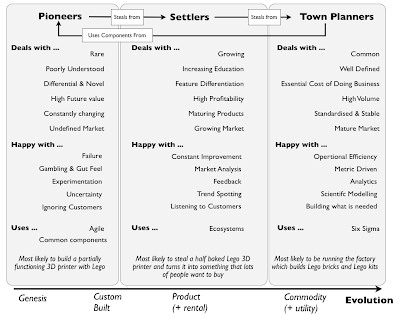
In my last post I talked about 4 dimensions that determine what kind of product manager an organization needs:
- Number of employees in the organization
- Number of users for your product
- Nature of the product
- Culture of the organization
Different types of organization and product expect/require different types of product management. We all say “product management” but we can mean very different things when we say it, depending on where the organization and product is along these four dimensions.
Here is an example based on a real experience of mine to illustrate this. It was when I was at Rated People, probably about 2010. It shows how the decision-making around the product (i.e. the product management) was informed by these four dimensions.
Rated People is a marketplace where home-owners post jobs they need done. Each job is notified to relevant tradespeople who can then choose to bid for that job or not. The system figures out if a tradesperson is relevant based on the type of work they do (plumbing, carpentry etc) and which areas they work in.
Which areas they work in was originally set by giving a central address and a distance. The system would calculate a circle using the distance as the radius. This was problematic because it didn’t reflect the reality of where people would travel to for work. Famously, London is split into North and South parts by the river Thames. Crossing the river can be time-consuming. People on the north side are more likely to spend more time on the north side of the river and those on the south to stay on the south side more.
We had three different ideas about how to address this problem.
First approach: Pave The Cow Paths. User testing showed that tradespeople generally thought of their work areas based on postcodes. So we could have come up with a solution that would let you enter a list of postcodes somehow, either by clicking on a map or by writing them into a form.
Second approach: Use the latest tech. In 2010 we now had the ability to draw any shape on a map. This seemed quite neat but when we then put it through user testing, our users found it very frustrating to draw the shape they wanted. This feature would have been a complete non-starter for our users.
Third approach: Lateral-thinking application of new tech. This is what we ended up going with. We approximated a circle with an octagon and allowed the user to drag the corners around. This worked well because if you were happy with the auto-generated circular area, the octagon was pretty much good enough for you. If you wanted to change the area then you could pretty well draw any shape you wanted by dragging the corner points. Hat tip to the mighty Oleg Roshka who did all the heavy lifting to make this feature happen.
The Lateral-thinking application of new tech suited us at the time because of where we were against the four dimensions:
- We were a relatively small organization and so could easily get a few key people on a call together to figure out the right solution together
- We had a relatively high number of customers (10’s of thousands) who weren’t particularly tech-savvy
- We wanted this part of the product to be a differentiator compared to the competition (the tradespeople are the paying side of the marketplace)
- The founder liked relatively elegant tech solutions that generalized well
It’s not a case that the other approaches were worse. They would have been more appropriate in different circumstances. The use the latest tech could have worked if our user base was more tech-savvy, for example. Pave the cow paths could have worked but it would have needed a fair amount of fine-tuning after release because different people, in different parts of the country, needed different levels of granularity to define their work areas.
The organization valued and needed this Lateral-thinking application of new tech at the time. That doesn’t suit all products and all organizations.
Here’s an example where pave the cow paths was the right approach. It’s from no less than Facebook and their photos product in 2005:
[E]very development in the Facebook photos product can be linked to that moment in 2005 when the team saw how people were using the photos: “Instead of trying to change people’s behaviour, they codified it.”
https://www.mindtheproduct.com/paving-cow-path-and-other-stories-by-simon-cross/
Facebook started 2005 with 1 million active users and ended with 5 million. This would have meant a lot of engineering challenges around scalability and stability and/or a lot of firefighting to keep the site up and working well. Accel Partners made their $13m investment into Facebook in 2005 which would have meant a lot of hiring. Based on this, some educated guessing about how Facebook would have measured up against the four dimensions:
- Relatively small organization but going through a lot of hiring and organizational change
- Very large user base who were young and relatively tech-savvy
- The product team was up against more established competitors in the photo space, and so had to find a relatively simpler way of getting more activity on Facebook photos
- The culture was about “moving fast and breaking things”
In this context, it made a lot of sense for the user-facing side of the PM team to get to grips with user behaviour and codify it. If it didn’t work to increase user activity they could pivot to a different idea.
I’m using Facebook as an example because it’s a well-known company that was explicitly following a pave the cow paths philosophy. Please don’t fall victim to survivorship bias and assume that dropping a 2005 Facebook PM into another organization would magically fix things1.
It’s horses for courses. Different organizations and products expect and need different things from their product managers2. We make things harder for ourselves by describing this all under one job title: “product manager” when in reality we mean a lot of different things depending on the context.
With all this said, do you want to see the Rated People feature I was talking about? Of course you do, and you’re in luck because it seems this feature worked well from a user point of view: it’s still there nearly 15 years later.
Here’s an example from DJC Contractors. I’m going to imagine that they live somewhere around the L or the o of London given that they are happy to go further north-west than they are south-east.

Here’s one for Comforooms ltd who are keen on the Western side of London.

On the other hand, Light Electrics, below, works on the Eastern side of London and surrounding areas. They are happy to work in Dartford but apparently don’t want to go to Croydon or as far as Watford. So I’m going to guess they are based relatively close to Chelmsford.

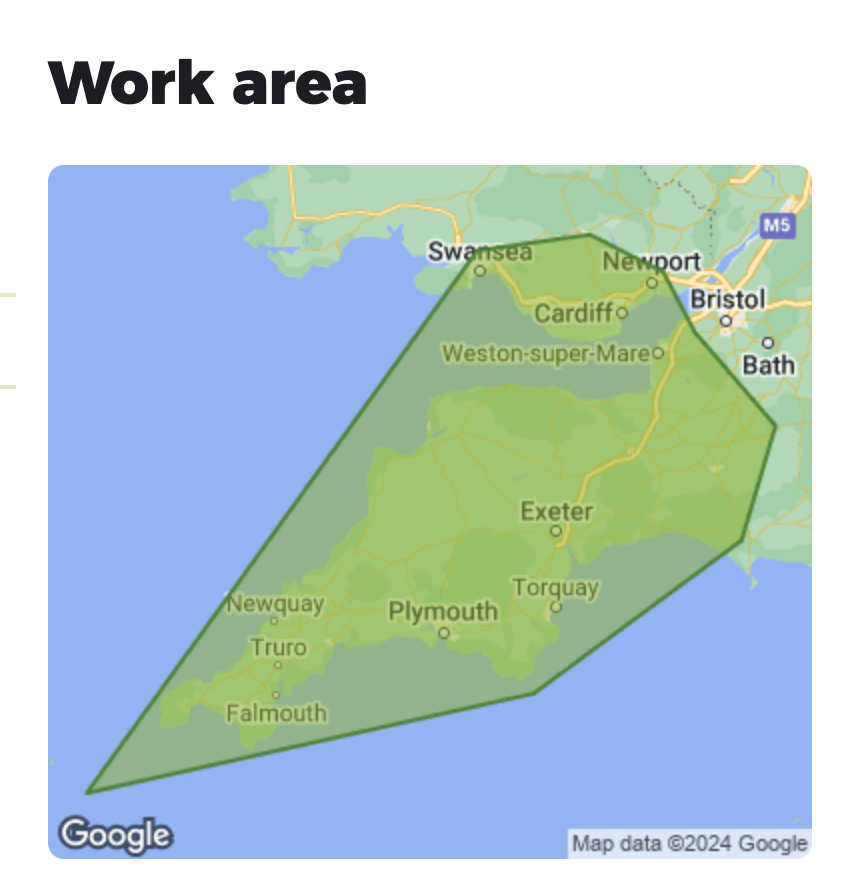
Or getting away from the capital, below are Next Gen Driveways who cover the whole of the South West of England, Swansea, Cardiff and Newport but have explicitly excluded some major local cities/towns (Bristol and Bath).
- If anything, this Facebook example is a good counterpoint to the prevailing wisdom that you should not be paving cow paths, depending on the context of the organization and the product ↩︎
- Even in this Facebook example, I’d expect that a PM working on the advertiser side of the business would treat things differently because those are the paying customers. ↩︎